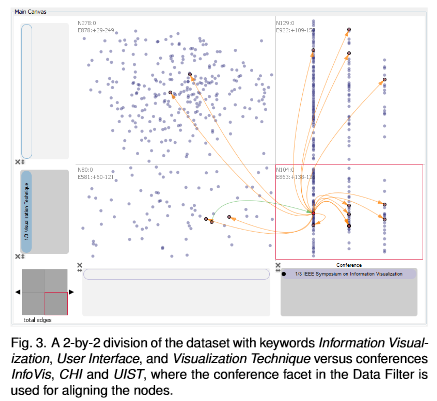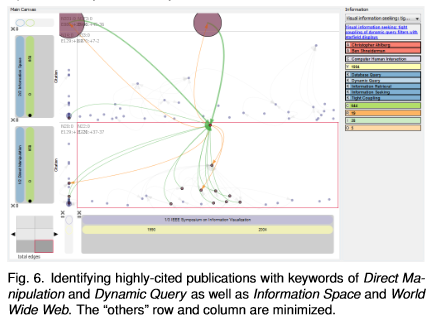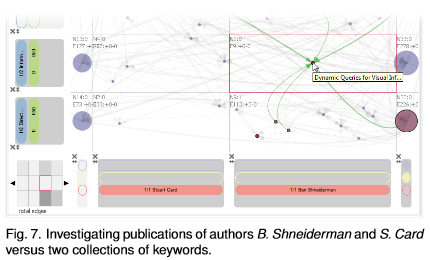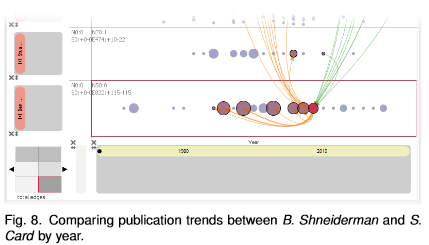
Contributors:
Tommaso Elli, Adam Bradley, Christopher Collins, Uta Hinrichs, Zachary Hills, and Karen Kelsky
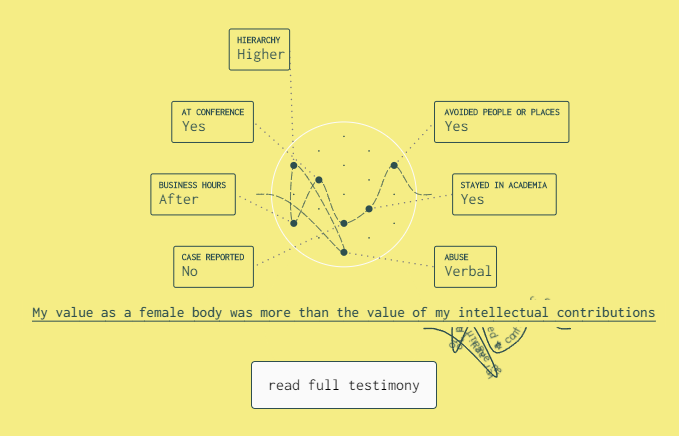
As researchers and members of the academic community, we felt that the issue of sexual harassment goes too often under-reported and we decided to give visibility to it using data visualization as a communicative medium. We present a data visualization project aimed at giving visibility to the issue of sexual harassment in the academic community.
The data you are about to see comes from an anonymous online survey aimed at collecting personal experiences. The survey was issued in late 2017 and, through it, more than 2000 testimonies were collected. This data is highly personal and sensitive. We spent significant effort identifying suitable ways to handle and represent it, to show the large dataset, but also honour the individual experiences.
Explore the visualization at tiedinknots.io
Publications
-
[pods name="publication" id="4173" template="Publication Template (list item)" shortcodes=1]
Acknowledgements
This work was supported by NSERC Canada Research Chairs, the Canada Research Chairs, and DensityDesign.