Contributors:
Rafael Veras Guimaraes, Julie Thorpe, and Christopher Collins
Summary
What is the meaning within a password? And, how does the meaning in your password relate to security risks? In our research into the ‘secret language of passwords,’ we have investigated the numerical and textual patterns from a semantic (meaning) point of view. Where prior research investigated letter and number sequences to expose vulnerable passwords, such as “password123,” our research has delved into the composition of seemingly complex passwords such as “ilovedan1201” or “may101982” and revealed common patterns. In these cases, the patterns of <I><love><male-name><number> and <month in letters><day in numbers><year after 1980 in numbers> are common patterns which, once learned, can be used to generate password guesses, such as “IloveMike203” and “July022001”.
Using linguistic analysis and interactive visualization techniques, we have investigated the patterns of date-like numbers in passwords, and the meaning and relationships between types of words in passwords. The resulting analysis guided our creation of a password guessing system (not available to the public!) which on several measures is better than any prior published result. The exposed vulnerabilities are motivating our ongoing work into new ways to help people create semantically secure passwords. This research contributed to a major story in the New York Times Magazine on the Secret Life of Passwords.
Our research started with the many large password leaks that were made publicly available on the Internet. In particular, the 32 million passwords from the RockYou website, exposed in 2009.
Our published research was conducted in two phases:
Date and Numbers
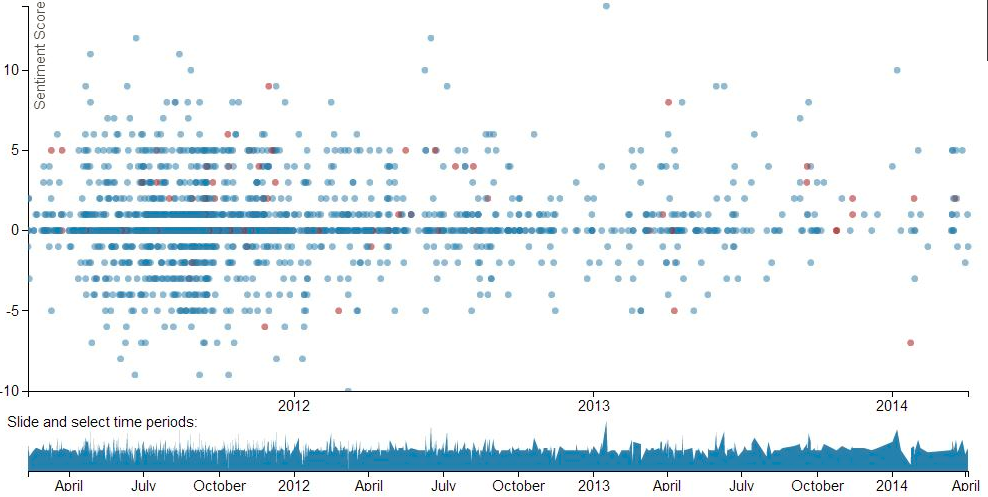
We started exploring date patterns, as 24% of the RockYou passwords contain a numeric sequence of at least 4 digits. So we wondered whether or not these sequences are dates, and if so, are there any temporal patterns? Our analyses found that 6% of these passwords (almost 2 million accounts!) contain numbers that match a date. To facilitate exploration of the patterns in the choice of dates, we created an interface that allows one to find the frequency that each day, month, year or decade (back to the year 1900) is referred to, as well as the corresponding passwords. We did not count passwords with numbers that are more likely to be keyboard patterns than dates, such as “111111”. Exploring the data through this interface, we confirmed some predictable patterns, such as the preference for dates that have repeated days and months (e.g., 08/08/1989), but also uncovered hidden ones, such as a consistent preference for the first two days of months, holidays, and a few notorious dates (e.g., Titanic accident) . For a detailed report on this work please read our paper or try our exploratory interface.
Words and Building a Password Grammar
In the second part of this research, we turned our attention to semantic patterns in the choice of words. Employing natural language processing techniques, we broke each password into words and classified the words according to their syntactic (grammar) function and semantic (meaning) content. The result is a rich model representing the syntactic and semantic patterns of a collection of passwords. With this model, we can rank the semantic categories to find that “love” is the most prevalent verb in passwords, “honey” is the most used food-related word, and “monkey” is the most popular animal, for example. Contrary to reported psychology research, we found that many categories related to sexuality and profanity are among the top 100. Our work also brought insight into the relations between concepts; for example, our model shows that a male name is four times more likely to follow the string “ilove” than a female name. Our paper, published in the NDSS Symposium 2014, discusses the security implications of our work. In summary, we show that the security provided by passwords is overestimated by methods that do not account for semantic patterns.
Online Demos
Try the dates visualization yourself!
Try the words visualization yourself!
Software
Media Coverage
Our research has also been featured in additional media, including:
- UOIT researchers crack down on password security in wake of Heartbleed (Julie Thorpe speaks to durhamregion.com)
- Change your password: A lesson from Russian website hackers (Christopher Collins speaks to durhamregion.com)
- Rogers TV Durham Now, September 2014 (all team members describe our work to Neil McArtney; includes the work of Julie Thorpe, Amirali Salehi-Abari (U Toronto), and Brent MacRae on GeoPass)
- Follert, Jillian. “From the Enigma Machine to Online Passwords: UOIT Looks at Keeping Secrete Information Secret”, Metroland DurhamRegion.com, March 13, 2018
- Walker, Anna-Kaiser. “Protect Yourself Against Identity Theft”, Reader’s Digest, March 1, 2018
- Spencer, Susan. “A World Beyond Passwords”, CBS Sunday Morning, February 19, 2017 (International television)
- Lynch, Laura. “Passwords” CBC Radio One: The Current, February 13, 2017 (National and online radio interview)
- Urbina, Ian. “The Secret Life of Passwords” New York Times Magazine, November 19, 2014 (International magazine and web)
We have also been featured on UOIT Homepage, including an article entitled “Heartbleed update: UOIT researchers analyze why consumers use weak passwords“.
Publications
-
[pods name="publication" id="4365" template="Publication Template (list item)" shortcodes=1]
[pods name="publication" id="4398" template="Publication Template (list item)" shortcodes=1]
[pods name="publication" id="4347" template="Publication Template (list item)" shortcodes=1]
Acknowledgements
Thanks to undergraduate alumni Jeffrey Hickson and Swapan Lobana who worked as research assistants on this project, and to the funding agencies who supported this work.