Contributors:
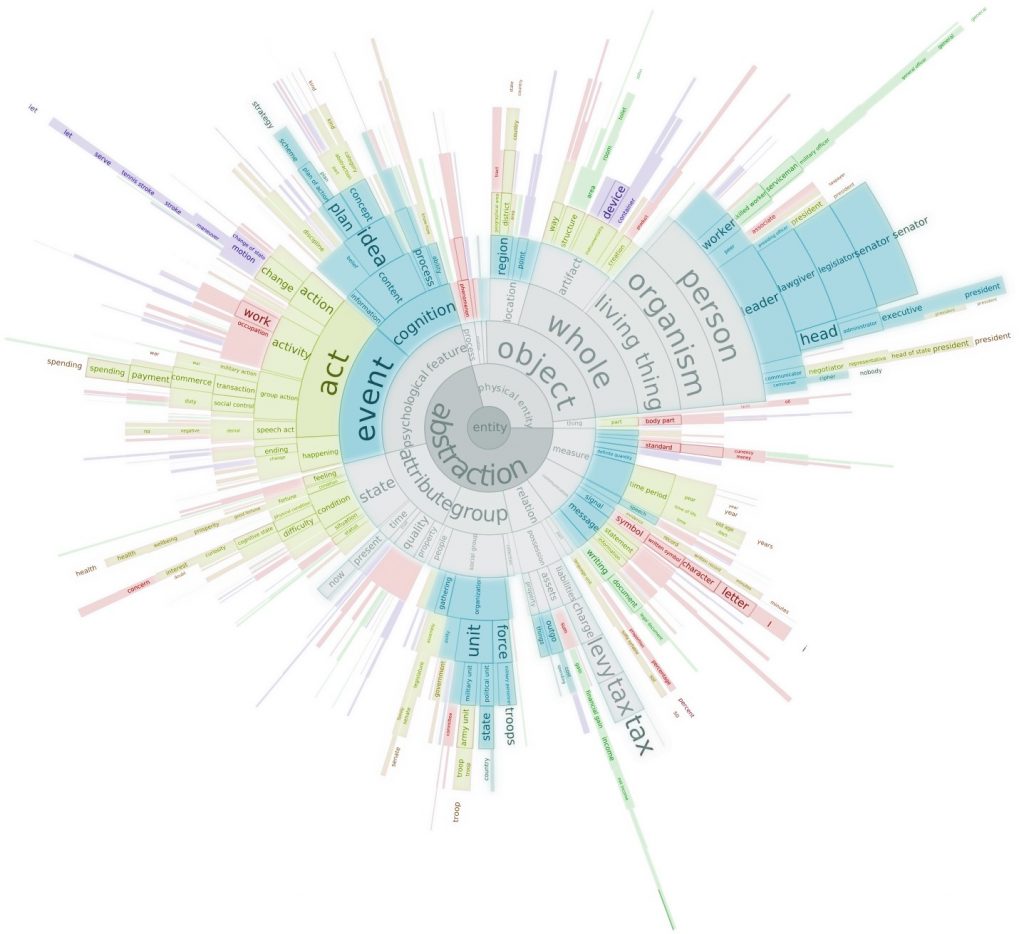
In this paper, we propose a new approach for adjusting the level of abstraction of hierarchical visualizations as a function of display size and dataset. Using the Minimum Description Length (MDL) principle, we efficiently select tree cuts that feature a good balance between clutter and information. We present MDL formulae for selecting tree cuts tailored to treemap and sunburst diagrams and discuss how the approach can be extended to other types of multilevel visualizations. In addition, we demonstrate how such tree cuts can be used to enhance drill-down interaction in hierarchical visualizations by enabling quick exposure of important outliers. The paper features applications of the proposed technique on treemaps of the Directory Mozilla (DMOZ) dataset (over 500,000 nodes), and on the Docuburst text visualization tool (over 100,000 nodes).
Validation is done with the feature congestion measure of clutter in views of a subset of the current DMOZ web directory. The results show that MDL views achieve near-constant clutter levels across display resolutions. We also present the results of a crowdsourced user study where participants were asked to find targets in views of DMOZ generated by our approach and a set of baseline aggregation methods. The results suggest that, in some conditions, participants are able to locate targets (in particular, outliers) faster using the proposed approach.
Check out our GitHub Repository for source code related to this project.
The slides from our VIS 16 presentation are available here.
Publications
-
[pods name="publication" id="4278" template="Publication Template (list item)" shortcodes=1]
[pods name="publication" id="4350" template="Publication Template (list item)" shortcodes=1]
Acknowledgements