Contributors:
Jessica Zipf, Mariana Shimabukuro, Shawn Yama, and Christopher Collins
What is Card-it?
Card-it is a web application for learning Italian verb morphology, in other words, Italian verb conjugations. Unlike other flashcard applications (i.e., Anki), Card-it’s offers (1) the semi-automatic creation of cards using a Finite-State Morphological (FSM) analyzer, reducing repetitive labour and human error inputting the morphological data, and (2) the possibility of classroom integration with student analytics supporting students, teachers and autonomous learners of Italian as a second language.
How was Card-it created?
Card-it was born from a collaboration between two Ph.D. students: Mariana Shimabukuro (Ontario Tech University) and Jessica Zipf (University of Konstanz). As a computational linguist, Jessica focuses on rule-based morphological tools to support second language acquisition and computer-assisted language learning (CALL). As a computer scientist, Mariana is trained in human-computer interaction (HCI); her work focuses on data-driven and learner-centred design for language learning applications to empower second language learners towards autonomy. Combining the interests and expertise of these two, Card-it features a learner-centred design providing an NLP-based approach to creating the study content and flexibility for curating and studying flashcards with informative learner feedback. Shawn Yama is also a valuable member of this project; Shawn was a research assistant who was responsible for most of the implementation of Card-it during his undergraduate studies.
Is Card-it available in other languages?
Unfortunately, Card-it only supports learners of Italian at the moment. However, Card-it features a modularized architecture which makes it easily expandable to other languages as long as we can provide it with the FSM or an extensive schema of verb forms in a different target language. Other modules in Card-it, such as its user interface, classroom, and interaction features, are applicable to any other language.
If you have the resources or interest in adapting Card-it to a different language, please contact us, and we will be happy to work with you to make it happen.
Video Presentation from EUROCALL 2021
Other language learning projects:
See more about Card-it in its demo and related publications:
Try Card-it Yourself: DEMO
Although Card-IT is still in the latter stages of development, you can try out the demo at cardit.vialab.ca by logging in using demo@email.com with the password livecardit.
Card-it at the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023)
M. Shimabukuro, J. Zipf, S. Yama, and C. Collins. 2023. Evaluating Classroom Potential for Card-it: Digital Flashcards for Studying and Learning Italian Morphology. In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), pages 130–136, Toronto, Canada. Association for Computational Linguistics.
- Link to the poster: Card-it Poster – BEA 2023
- Link to the demo video: Card-it DEMO
Card-it Versus: Bachelors Theses 2022
S. Yama, “Card-IT Versus: A Competitive Multiplayer Game for Testing Italian Verb Morphology,” Bachelors Thesis, 2022.
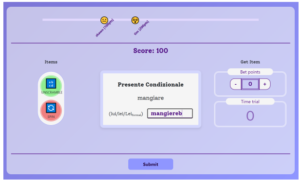
Card-it Versus is a gamified multiplayer version of Card-it. Using Card-it as the underlying system, Shawn added a module, “Card-it Versus”. In this extension, multiple players can compete for points while answering flashcard quizzes on Italian conjugations synchronously. While they compete to finish their quizzes the fastest, players are rewarded with items designed to boost their own performance or to sabotage their opponents. For example, an item can be used to erase or scramble your opponent’s letter, which may lead to them losing accuracy and points! This extension is not available in the live version of Card-it, but it exemplifies how Card-it can be expanded into adjacent projects.
Online presented talk at EuroCALL 2021
J. Zipf, M. Shimabukuro, and C. Collins, Card-IT: a Dynamic FSM-based Flashcard Generator for Learning
Italian Verb Morphology, Abstract presented at EuroCALL (online), 2021.
Extended Abstract
We report on a novel approach to training and testing Italian verb morphology by developing a flashcard application. Instead of manually curated content, this application integrates a large-scale finite-state morphological (FSM) analyzer which both analyzes a user’s input and dynamically generates specific verb forms (flashcards). FSMs are widely used in natural language processing as part of a system’s text preprocessing pipeline. Our main contribution is to leverage the FSM as the core component to implement a dynamic verb generator based on defined morphological features or return a form’s morphological analysis. Therefore, we developed Card-IT, a web-based application powered by the FSM that uses flashcards as a way for learners to utilize the analyzer in a user-friendly manner. The two-sided cards represent both functions of the FSM: analysis and generation.
Card-IT can be used to quickly analyze a form or to look up entire verb paradigms where the users (teachers or learners) can freely define morphological features, such as tense, mood, etc. Optionally, they can choose to leave any feature unspecified. Depending on the user’s selection, the application returns the corresponding flashcards, which can be saved and organized into a new or existing deck for testing and training. The organization and sorting of decks and cards allow learners to study verbs based on their individual study interests/needs e.g., one might choose to focus on subjunctive forms or past tense only. Additionally, teachers can create decks to provide their students with specific learning content and exercises.
As studies have shown, knowledge of the underlying linguistic concepts benefits the acquisition of a new language (e.g., Heift, 2004). Therefore Card-IT embeds explanations of linguistic terms (e.g., mood, conditional) using visual components, to allow learners to identify linguistic patterns and raise their metalinguistic awareness over time. Moreover, in Card-IT all linguistic terms are provided in the target language.
We plan on evaluating Card-IT with experts, Italian teachers, and implementing their feedback before evaluating it with students. At its current version, Card-IT offers three functions: (1) form analysis and look-up as mentioned above; (2) training, and (3) testing. In training using the self or teacher-curated decks generated with the help of the FSM, learners can study and learn verbs along with their inflectional forms. The testing mode consists of two different exercises: a conjugation quiz that prompts the user to type a form based on provided linguistic specification; and a tense quiz that offers a form asking the user to pick the corresponding tense out of three. Optimally, the learner may also select a mixed-mode that combines both testing exercises.
Feedback plays a crucial role in learning in that it must be both informative and motivating, yet not discouraging (Livingstone, 2012). Whenever the learner enters an incorrect verb form, the FSM the system checks whether it corresponds to any other tense/mood configurations. If so, the system reports it to the user to provide targeted feedback on errors with indications of how to improve rather than just an (in)correct message.
Publications
-
[pods name="publication" id="9343" template="Publication Template (list item)" shortcodes=1]
[pods name="publication" id="9157" template="Publication Template (list item)" shortcodes=1]