Contributors:
Christopher Collins, Natalia Andrienko, Tobias Schreck, Jing Yang, Jaegul Choo, Ulrich Engelke, Amit Jena, and Tim Dwyer
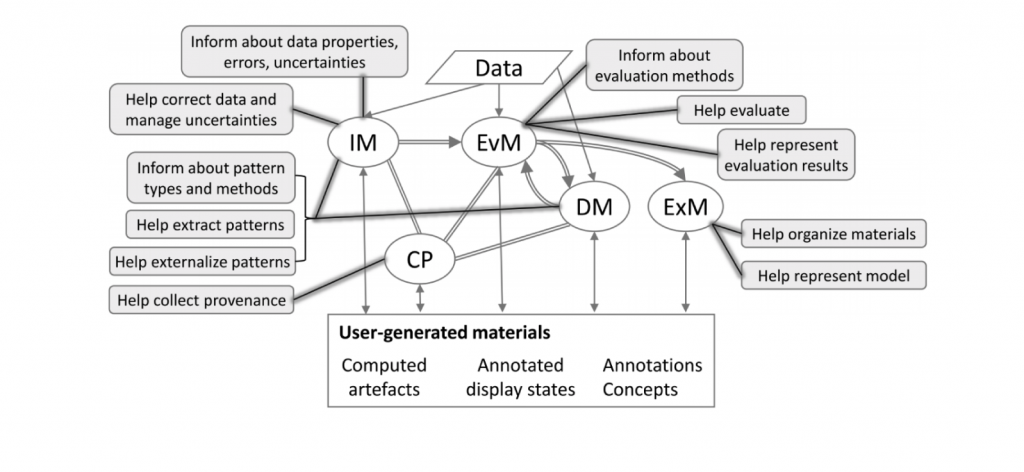
In this paper, we list the goals for and the pros and cons of guidance, and we discuss the role that it can play not only in key low-level visualization tasks but also the more sophisticated model-generation tasks of visual analytics. Recent advances in artificial intelligence, particularly in machine learning, have led to high hopes regarding the possibilities of using automatic techniques to perform some of the tasks that are currently done manually using visualization by data analysts. However, visual analytics remains a complex activity, combining many different subtasks. Some of these tasks are relatively low-level, and it is clear how automation could play a role—for example, classification and clustering of data. Other tasks are much more abstract and require significant human creativity, for example, linking insights gleaned from a variety of disparate and heterogeneous data artifacts to build support for decision making. In this paper, we outline the potential applications of guidance, as well as the inputs to guidance. We discuss challenges in implementing guidance, including the inputs to guidance systems and how to provide guidance to users. We propose potential methods for evaluating the quality of guidance at different phases in the analytic process and introduce the potential negative effects of guidance as a source of bias in analytic decision-making.
Publications
-

C. Collins, N. Andrienko, T. Schreck, J. Yang, J. Choo, U. Engelke, A. Jena, and T. Dwyer, “Guidance in the human–machine analytics process,” Visual Informatics, 2018.
@Article{col2018b,
author = {Christopher Collins and Natalia Andrienko and Tobias Schreck and Jing Yang and Jaegul Choo and Ulrich Engelke and Amit Jena and Tim Dwyer},
journal = {Visual Informatics},
publisher = {Elsevier B.V.},
title = {{Guidance in the human–machine analytics process}},
year = {2018},
}
Acknowledgements
This paper is the direct result of an NII Shonan Meeting at the Shonan Village Center in Japan. We acknowledge the hospitality of the Center in making this research possible. This work was partly supported by the Natural Sciences and Engineering Research Council of Canada (NSERC), [grant RGPIN-2015-03916], the Fraunhofer Cluster of Excellence on ‘‘Cognitive Internet Technologies’’ and by the EU through project Track&Know (grant agreement 780754).