Contributors:
Mennatallah El-Assady, Rita Sevastjanova, Bela Gipp, Daniel Keim, and Christopher Collins
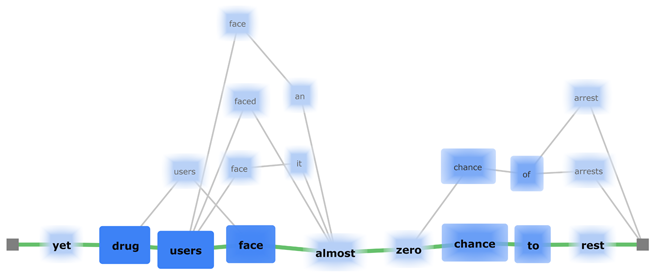
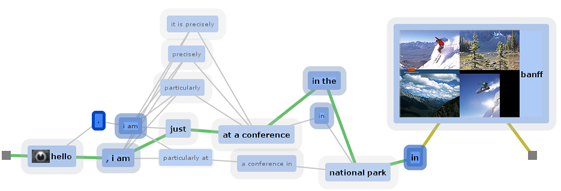
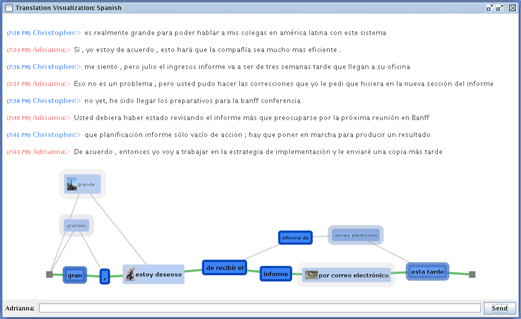
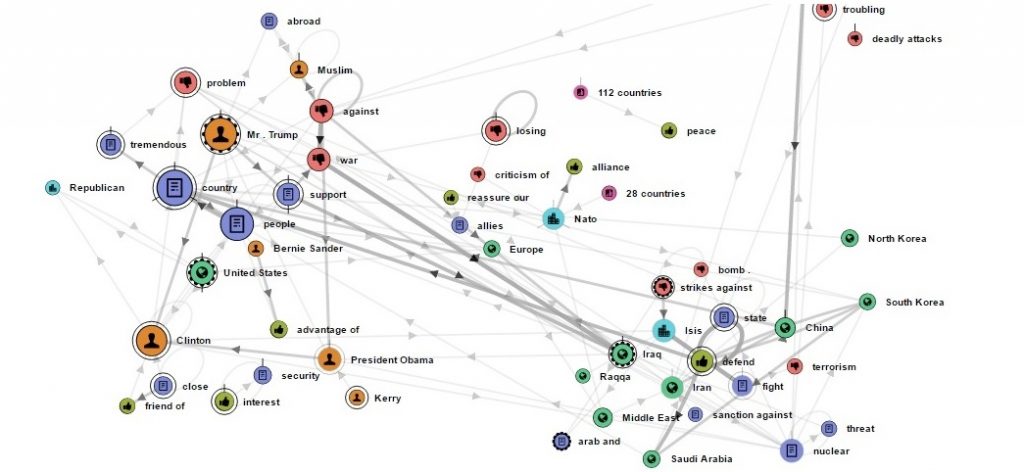
We present NEREx, an interactive visual analytics approach for the exploratory analysis of verbatim conversational transcripts. By revealing different perspectives on multi-party conversations, NEREx gives an entry point for the analysis through high-level overviews and provides mechanisms to form and verify hypotheses through linked detail-views. Using a tailored named-entity extraction, we abstract important entities into ten categories and extract their relations with a distance-restricted entity-relationship model. This model complies with the often ungrammatical structure of verbatim transcripts, relating two entities if they are present in the same sentence within a small distance window. Our tool enables the exploratory analysis of multi-party conversations using several linked views that reveal thematic and temporal structures in the text. In addition to distant-reading, we integrated close-reading views for a text-level investigation process. Beyond the exploratory and temporal analysis of conversations, NEREx helps users generate and validate hypotheses and perform comparative analyses of multiple conversations. We demonstrate the applicability of our approach on real-world data from the 2016 U.S. Presidential Debates through a qualitative study with three domain experts from political science.
For a demo, please visit: http://visargue.inf.uni-konstanz.de/
Publications
-
[pods name="publication" id="4266" template="Publication Template (list item)" shortcodes=1]