Contributors:
Eric Alexander, Chih-Ching Chang, Mariana Shimabukuro, Steven Franconeri, Christopher Collins, and Michael Gleicher
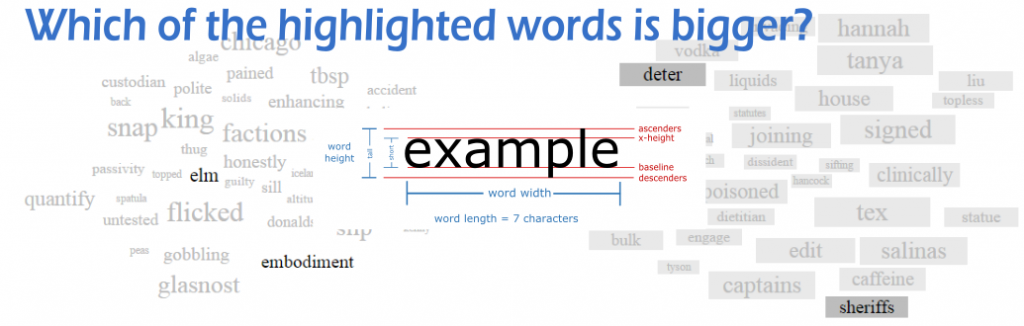
Many visualizations, including word clouds, cartographic labels, and word trees, encode data within the sizes of fonts. While font size can be an intuitive dimension for the viewer, using it as an encoding can introduce factors that may bias the perception of the underlying values. Viewers might conflate the size of a word’s font with a word’s length, the number of letters it contains, or with the larger or smaller heights of particular characters (‘o’ vs. ‘p’ vs. ‘b’). We present a collection of empirical studies showing that such factors-which are irrelevant to the encoded values-can indeed influence comparative judgements of font size, though less than conventional wisdom might suggest. We highlight the largest potential biases and describe a strategy to mitigate them.
Publications
-
[pods name="publication" id="4308" template="Publication Template (list item)" shortcodes=1]
[pods name="publication" id="4269" template="Publication Template (list item)" shortcodes=1]