Contributors:
Mariana Shimabukuro, Jessica Zipf, Mennatallah El-Assady, and Christopher Collins
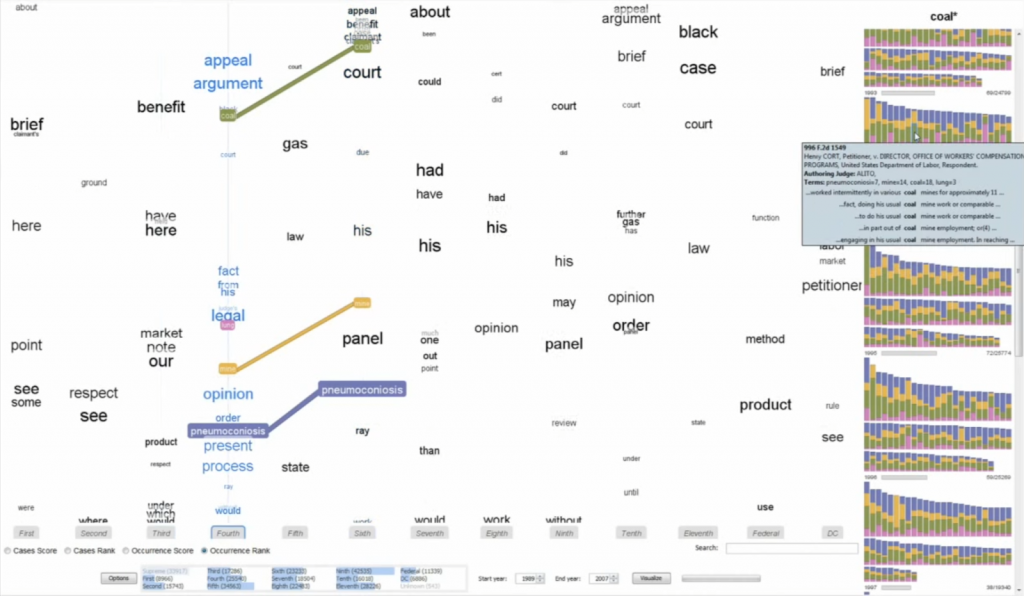
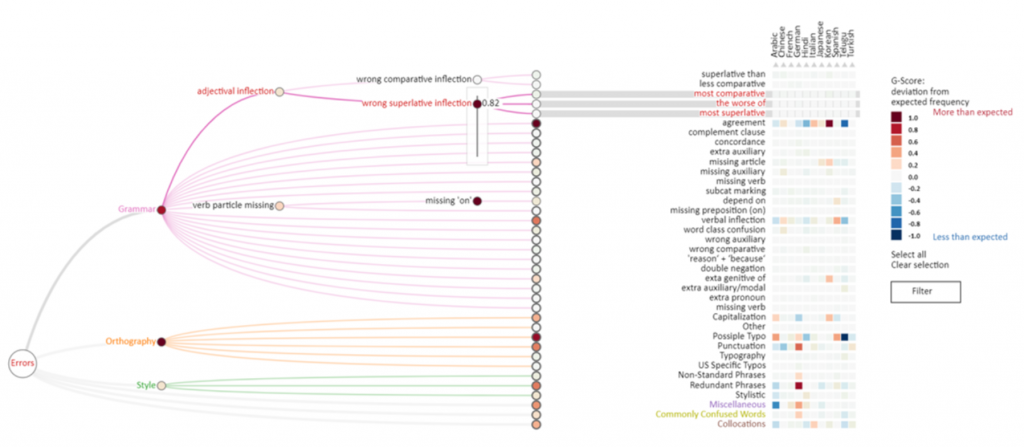
This paper presents a visualization technique for cross-linguistic error analysis in large learner corpora. H-Matrix combines a matrix, which is commonly used by linguists to investigate cross-linguistic patterns, with a tree diagram to aggregate and interactively re-weight the importance of matrix rows to create custom investigative views. Our technique can help experts to perform data operations, such as feature aggregation, filtering, ordering and language comparison interactively without having to reprocess the data. H-Matrix dynamically links the high-level multi-language overview to the extracted textual examples, and a reading view where linguists can see the detected features in context, confirm and generate hypotheses.
The source code for H-matrix can be found on our Github.
Publications
-
[pods name="publication" id="4194" template="Publication Template (list item)" shortcodes=1]
Acknowledgements
The authors wish to thank the reviewers, our colleagues, and domain experts. This work was supported in part by NSERC Canada Research Chairs and a grant from SFB-TRR 161. This research has also been made possible by the Ontario Research Fund, funding research excellence.